สรุปสิ่งที่ได้รับจากการเรียนการเตรียมฝึกประสบการณ์วิชาชีพบริหารธุรกิจ
สิ่งที่ข้าพเจ้าได้รับจากการเรียนวิชานี้นั้น มีคุณค่าและประโยชน์มากมายมหาศาลเพราะการที่ข้าพเจ้าได้เรียนรู้ถึงวิธีการปฏิบัติหน้าที่ที่เป็นระบบระเบียบในการทำงานจะทำให้งานนั้นมีประสิทธิภาพมากขึ้นสิ่งสำคัญคือการร่วมมือร่วมใจกันทำงาน แบ่งแยกแยะว่าไรคือประโยชน์อะไรคือปัญหาและอุปสรรค วิชานี้สอนให้ข้าพเจ้าได้เรียนรู้ในเรื่องของการมีจิตใต้สำนึกที่ดีต่อการปฏิบัติให้กับตัวเองและผู้อื่นอย่างมีคุณภาพ ข้าพเจ้าคาดว่าจะสิ่งที่ข้าพเจ้าได้รับจากการเรียนวิชานี้สามารถที่จะนำความรู้ความสามารถในเรื่องต่างที่อาจาย์และวิทยากรบรรยาเป็นสิ่งที่จะนำไปใช้ในชีวิตการทำงานของข้าพเจ้าได้เป็นอย่างมากในอนาคตข้างหน้าวิชานี้ทำให้ข้าพเจ้ารู้สึกยินดีและประทับอาจาย์ผู้สอนที่ค่อยว่ากล่าวตักเตือนให้กับข้าพเจ้าและเพื่อนทุกๆคน ด้วยการที่จะปฏิบัติกระทำสิ่งใดนั้นวิชานี้สอนให้รู้ถึงความประพฤติปฏิบัติตนให้อยู่ในศีลธรรมจริยธรรมอันดีงานและสอนให้รู้ถึงความไม่ประมาทที่กระทำสิ่งใดๆ ให้ลุล่วงถึงความสมเร็จได้ สุดท้ายนี้วิชานี้ได้สอนให้ข้าพเจ้ารู้ถึงปัญหาและการแก้ปัญหาที่ถูกต้องว่าสิ่งใดคือปัญหาอุปสรรสิ่งใดคือประโยชน์ ข้าพเจ้า จะนำความรู้ที่ได้เรียนจากวิชาเตรียมฝึกประสบการณ์วิชาชีพไปประกอบอาชีพที่สุจริตต่อสังคมและผู้อื่น จะปฏิบัติหน้าที่ให้ดีที่สุด และอยู่ในศีลธรรมจริยธรรม ของพระผู้มีพระภาคเจ้าด้วยความไม่ประมาท
สิ่งที่ข้าพเจ้าได้รับจากการฝึกประสบการณ์วิชาชีพ
1.มีศีลธรรมจริยธรรม คือ การประพฤติดีงาม ประพฤติชอบ ประพฤติควร อะไรดีก็ทำ อะไรไม่มีก็ไม่ทำ
2.มีความเมตตา กรุณา คือ การที่มีความเมตตาต่อผู้อื่น ไม่เบียดเบียนผู้อื่นเป็นสิ่งประเสริฐ
3.ตรงต่อเวลา คือ การที่ประพฤติให้ตัวเรานั้นติดเป็นนิสัย ไม่ตามเวลา แต่ต้องเดินก่อนเวลา ถึงจะทันเวลา
4.การพูดจา คือ การใช้คำพูดที่ไพเราะ ไม่พูดคำหยาบคาย พูดในสิ่งที่ควรพูด และไม่พูดในสิ่งที่ไม่ดี
5.ความรู้ คือ เราต้องมีสติอยู่เสมอ ต่อการกระทำสิ่งนั้น ถ้าขาดสติ ก็จะไม่เกิด ความรู้ ไม่เกิดปัญญา
6.ความเหมาะสม คือ ทำให้เรานั้นมีความคิดว่าสิ่งใดที่เหมาะในการทำงาน ที่ได้รับ
7.มีบุคลิกภาพที่ดี คือ ทำให้การวางตัวได้ถูกต้อง ดูมีสง่าราศี และแต่งกายให้สุภาพเรียบร้อย
8.มีระเบียบวินัย คือ การประพฤติปฏิบัติ ในกฎข้อบังคับของผู้บังคับบัญชา
9.ความคิดในแง่ดี คือ การคิดในสิ่งที่ดีๆ ไม่คิดในแง่ลบ ถ้าคิดดีก็จะอยู่ในใจของผู้มีความดีใจก็จะเป็นเทวดา ถ้าเราคิดในสิ่งที่ไม่ดีก็จะเกิดความทุกข์ใจก็จะเป็นยักษ์
วันพฤหัสบดีที่ 15 ตุลาคม พ.ศ. 2552
วันเสาร์ที่ 19 กันยายน พ.ศ. 2552
DTS09/19/2009
Sorting ถ้าเราจำเป็นต้องเก็บและค้นหาข้อมูลอยู่เป็นประจำ การเก็บข้อมูลเราก็ต้องจัดเก็บให้เป็นระเบียบและง่ายในกระบวนการค้นหาข้อมูลเพื่อนำมาใช้ใหม่ เช่นการจัดเรียงหมวดหมู่ของหนังสือในห้องสมุดต้องมีการจัดการรายละเอียดของหนังสื่อต่างๆ ให้เป็นแฟ้มข้อมูลที่เรียงลำดับตามอักษร เป็นต้น และในการประกอบการต่างๆ ที่เกี่ยวข้องกับการใช้งานด้านคอมพิวเตอร์ก็มีการจัดเรียงลำดับของข้อมูลโดยวิธีใดวิธีหนึ่งแล้วแต่เรากำหนดทำไมเราจึงต้องศึกษาการเรียงลำดับข้อมูล (Sorting) เพื่อช่วยในการออกแบบอัลกอรึทึม เพราะการเรียงลำดับข้อมูล เป็นงานพื้นฐานที่ใช้ในโปรแกรมประยุกต์ต่างๆ ช่วยทำให้การเรียกใช้งานข้อมูลนั้นๆ มีความสะดวก รวดเร็ว ในการค้นหา มากกว่าการเรียกใช้ข้อมูลที่ไม่มีการลำดับ และทำให้เกิดเทคนิคใหม่ๆ ที่น่าสนใจและสำคัญอันได้แก่ Partial ,order ,recursion ,merge ,lists การจัดเก็บ
binary tree ในอาเรย์เป็นต้น อีกทั้ง อัลกอรึทึมที่ใช้เพื่อการเรียงลำดับข้อมูลแต่ละตัวมีข้อดีและข้อเสียแตกต่างกันขึ้นอยู่กับจำนวนชนิดของข้อมูล การกำหนดค่าเริ่มต้น ขนาด และค่าของข้อมูลที่จะทำการเรียงลำดับสิ่งสำคัญก็คือ เราต้องรุ้ว่าเรามีความต้องการอย่างไรเพื่อที่สามารถจะเลือก อัลกอรึทึมที่มีความเหมาะสมและสอดคล้องกับงานของเราได้
การเรียงข้อมูล สามารถแบ่งได้เป็น 2 ประเภทด้วยกันคือ
1. การเรียงข้อมูลแบบภายใจ (Intemal sorting) คือการเรียงลำดับข้อมูลโดยทั้งหมดต้องจัดเก็บอยู่ในหน่วยความจำหลัก (main memory) ที่มีการเข้าถึงข้อมูลได้เร็วโดยไม่จำเป็นต้องใช้หน่วยความจำสำรอง เช่นดิสก์ หรือเทปสำหรับการจัดเก็บชั่วคราว ใช้ในกรณีที่ข้อมูลไม่มากเกินกว่าพื้นที่ความจำเป็นกำหนดให้กับผู้ใช้
แต่ละราย
2. การเรียงข้อมูลแบบภายนอก (Extermal sorting) คือการเรียงลำดับข้อมูลที่มีขนาดใหญ่เกินกว่าที่จะสามารถเก็บไว้ใน พื้นที่ความจำหลักที่กำหนดให้ได้ในคราวเดียว ดังนั้นข้อมูลส่วนมากต้องเก็บไว้ในไฟล์ข้อมูลที่อยู่บนดิสก์ เทป เป็นต้น สำหรับการเรียงข้อมูลแบบภายนอกจะต้องคิดถึงเวลาที่ใช้ในการถ่ายเทข้อมูลจากหน่วยความจำชั่วคราวกับหน่วยความหลัก ด้วยเช่นกัน
อัลกอรึทึมสำหรับการเรียงข้อมูล จัดได้ 3 ประเภทใหญ่ๆ คือ
1. การเรียงลำดับแบบแลกเปลี่ยน (Exchange sort)
2. การเรียงลำดับแบบแทรก (Insertion sort)
3. การเรียงลำดับแบบเลือก (Selection sort)
Sorting Algorithms
Bubble sort
หลักของการเรียงแบบนี้คือ จะเปรียบเทียบและแลกแปลี่ยนข้อมูล 2 ค่าที่อยู่ติดกันในลักษณะที่เรากำหนดเช่นจากน้อยไปหามาก หรือ จากมากไปหาน้อย โดยจะทำการเปรียบเทียบข้อมูลทั้งชุดจนกว่าจะมีการเรียงลำดับทั้งหมดของขั้นตอนการทำงานของอัลกอรึทึม
Quick Sort
การเรียงลำดับในลักษณะนี้เป็นการปรับปรุงมาจากการเรียงลำดับแบบ Bubble เพื่อให้การเรียงลำดับนั้นเร็วขึ้นวิธีนี้เหมาะกับการเรียงข้อมูลที่มีจำนวนมาก หรือมีขนาดใหญ่ และเป็นวิธีการเรียงข้อมูลที่ให้ค่าเฉลี่ยของเวลาน้อยที่สุดเท่าที่ค้นพบวิธีหนึ่ง การเรียงลำดับแบบ Quick sort จะเป็นการเปรียบเทียบสมาชิกที่ไม่อยู่ติดกันโดยกำหนดข้อมูลค่าหนึ่ง เพื่อแบ่งชุดข้อมูลที่ต้องการเรียงลำดับออกเป็น 2 ส่วน จากนั้นจะทำการแบ่งย่อยชุดข้อมูล 2 ส่วนนั้นลงไปอีกทำแบบนี้ไปเรื่อยๆ จนข้อมูลแต่ละชุดมีสมาชิกเหลือเพียงตัวเดียงและทำให้ชุดข้อมูลทั้งหมดมีการเรียงลำดับ
Insertion Sort
insertion sort การเรียงลำดับที่ง่ายไม่ซับซ้อน เป็นการนำข้อมูลใหม่เพิ่มเข้าไปในชุดข้อมูลที่มีการเรียงลำดับอยู่แล้ว โดยข้อมูลใหม่ที่นำเข้ามาจะแทรกอยู่ใจตำแหน่งทางขวาของชุดข้อมูลเดิมและยังคงให้ข้อมูลทั้งหมดมีการเรียงลำดับ วิธีนี้เริ่มต้นโดยการเรียงลำดับ 2 ตัวแรกของชุดข้อมูล หลังจากนั้นเพิ่มข้อมูลตัวที่3เข้ามาจะมีการเปรียบเทียบค่ากับข้อมูล 2 ตัวแรก และแทรกอยู่ในตำแหน่งที่เหมาะสมและสำหรับการเพิ่มข้อมูลตัวต่อๆไปก็จะทำเหมือนเดิมจนข้อมูลทุกตัวมีการเรียงลำดับขั้นตอนการทำงาน
วันอาทิตย์ที่ 13 กันยายน พ.ศ. 2552
DTS08/13/09/2009
Graph กราฟเป็นโครงสร้างข้อมูลประเภทหนึ่งที่แสดงความสัมพันธ์ระหว่าง Vertex และ Edge กราฟจะประกอบด้วยกลุ่มของ Vertex ซึ่งจะแสดงในกราฟด้วยสัญญลักษณ์รูปวงกลมและกลุ่มของ Edge

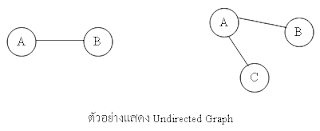
3.Cyclic Graph กราฟที่มีเส้นเชื่อมต่อระหว่าง vertex ที่ทำให้ vertex มีลักษณะเป็นวงจรปิด(Cycle)

(เส้นเชื่อมระหว่าง vertex) ใช้แสดงถึงความสัมพันธ์ระหว่าง vertex หากมี vertex ตั้งแต่ 2 vertex ขึ้นไปมีความสัมพันธ์ ใช้สัญลักษณ์เส้นตรงซึ่งอาจมีหัวลูกศร หรือไม่มีก็ได้
กราฟสามารถเขียนแทนด้วยสัญลักษ์ ดังนี้
G=(V,E)
G คือ กราฟ
V คือ กลุ่มของ vertex
E คือ กลุ่มของ edge
ตัวอย่างของกราฟในชีวิตประจำวัน เช่น กราฟของการเดินทางระหว่างเมือง ซึ่ง vertex คือกลุ่มของเมืองต่างๆ และ edge คือเส้นทางเดินระหว่างเมือง หรือ ในเครือข่ายคอมพิวเตอร์ (Computer Network) vertex ก็คือ กลุ่มของเครื่องคอมพิวเตอร์ หรือ โหนดต่างๆ และ edge ก็คือเส้นทางการติดต่อสื่อสารระหว่างโหนดต่างๆ เป็นต้น
ประเภทของกราฟ
แบ่งเป็น 3 ประเภทโดยแบ่งตามประเภทของ egdg คือ
1.Direct Graph กราฟแสดงทิศทาง เป็นกราฟที่แสดงเส้นเชื่อมระหว่าง vertex โดยแสดงทิศทางของการเชื่อมต่อด้วยกัน
2.Undirected Graph กราฟที่แสดงเส้นเชื่อมต่อระหว่าง vertex แต่ไม่แสดงทิศทางของการเชื่อมต่อ
3.Cyclic Graph กราฟที่มีเส้นเชื่อมต่อระหว่าง vertex ที่ทำให้ vertex มีลักษณะเป็นวงจรปิด(Cycle)
เส้นเชื่อมต่อระหว่าง vertex อาจจะแสงทิศทางหรือไม่แสดงทิศทางการเชื่อมต่อก็ได้
เส้นทาง (Path)
เส้นทางคือการเดินทางจาก vertex หนึ่งไปยังอีก vertex หนึ่งที่ต้องการ โดยผ่าน edge ที่เชื่อระหว่าง vertex ความของเส้นทาง คือจำนวนของ edge ในเส้นทางเดินนั้นว่ามีจำนวนเท่าไร ในการเดินทางจาก
vertex หนึ่งไปยังอีก vertex หนึ่งถ้าหากเส้นทางประกอบด้วย vertex จำนวน N ความยาวของเส้นทางจะเท่ากับ N-1
การแทนที่ด้วยกราฟเมตริกซ์
โครงสร้างข้อมูลประเภทกราฟสามารถใช้เมตริกซ์มาแสดงแทนได้โดยกราฟที่ประกอบด้วย vertex จำนวน
N vertex สามารถแทนที่ด้วยเมตริกซ์ขนาด N*N โดยค่าในเมตริกซ์จะประกอบด้วย ค่า 0 และ 1
ค่า 0 จะใช้แทนไม่มี edge ความยาว 1 เชื่อต่อจากต้นทางไปปลายทาง และ ค่า 1 จะใช้แทนมี edge ความยาว 1 เชื่อต่อจากต้นทางไปปลายทาง
วันพฤหัสบดีที่ 10 กันยายน พ.ศ. 2552
DTS07/01/09/2009
tree หรือ โครงสร้างข้อมูลแบบต้นไม้ ประกอบด้วยโหนด (Node) ซึ่งเป็นส่วนที่เก็บข้อมูลในทรีหนึ่งทรีจะประกอบไปด้วยรูทโหนด (root node) เพียงหนึ่งโหนด แล้วรูทโหนดก็สามารถแตกโหนดออกเป็นโหนด
ย่อยๆได้อีกหลายโหนดเรียกกันว่าโหนดลูก (Child node) เมื่อมีโหนดลูกแล้ว โหนดลูกก็ยังสามารถแสดงเป็นโหนดพ่อแม่ (Parent node) โดยการแตกโหนดออกเป็นโหนดย่อยๆ ได้อีก
ย่อยๆได้อีกหลายโหนดเรียกกันว่าโหนดลูก (Child node) เมื่อมีโหนดลูกแล้ว โหนดลูกก็ยังสามารถแสดงเป็นโหนดพ่อแม่ (Parent node) โดยการแตกโหนดออกเป็นโหนดย่อยๆ ได้อีก

Root Node จากรูป คือ โหนด A
Child Node หรือ โหนดลูก จากรูป B,C,D และ E เป็นโหนดลูกของ A
Parent Node หรือโหนดพ่อแม่ โหนด B ที่เป็นโหนดลูกของโหนด A ก็สามารถแตกออกเป็นโหนดย่อยๆได้แก่ F และ G ดัง นั้น B จึงเป็นโหนดพ่อแม่ของ F และ G ในทำนองเดียวกัน A ก็นเป็นโหนดพ่อแม่ของ
B,C,D และ E กิ่ง (branch or Edge) เป็นเส้นที่เชื่อมต่อระหว่างโหนดพ่อแม่กับโหนดลูก Brother node หรือโหนดพี่น้อง คือ โหนดที่มีพ่อแม่เดียวกัน เช่น B,C,D,E เป็นโหนดพี่น้องกันเพราะมีโหนดพ่อแม่เดียวกัน คือ โหนด A และ F และ G เป็นโหนดพี่น้องกันโดยมี B เป็นโหนดพ่อแม่
Leaf node คือ โหนดที่ไม่มีโหนดลูก จากรูปโหนดที่ไม่มีโหนดลูกได้แก่ F G H K J K L M
Baranch node คือ โหนดที่ไม่ใช่ Leaf node เช่น โหนด B C D E เรียกว่า Branch node
Degree คือ จำนวนลูกของโหนด x เช่น degree ของโหนด A = 4 ได้แก่ B C D E จำนวน degree ของโหนด B=2 จำนวน degree ของโหนด F=0 เนื่องจากโหนด F ไม่มีโหนดลูก
Direct Descendant node คือ โหนดที่มาทีหลังทันที จากรป B C D E เป็น direct descendant node ของโหนด A เพราะเป็นโหนดที่มาทีหลังทันที
Descendant node คือ โหนดลูกของโหนด x และโหนดที่ทุกโหนดที่แตกจากโหนดลูกของโหนด x ตัวอย่าง descendant ของโหนด A คือ ทุกโหนดที่เหลือในทรี
Binary tree มีลักษณะเหมือนกับ tree ปกติแต่มีคุณสมบัติพิเศษ คือ แต่ละโหนดจะมีโหนดลูกได้ไม่เกิน 2 โหนด หรือพูดอีกอย่างหนึ่งว่า แต่ละโหนดใน binary tree จะมีดีกรีได้ไม่เกิน 2
Complete Binary Tree
หรือต้นไม้ใบนารีแบบสมบูรณ์ มีลักษณะคล้ายกับ Binary Tree แต่มีข้อพิเศษ คือ
1. ทุกโหนดที่ไม่ใช่ Leaf node จะต้องมีโหนดลูก 2 โหนด
2. Leaf node จะต้องอยู่ในระดับเดียวกัน
Binary Search Tree
จะมีลักษณะคล้ายกับ Binary Tree แต่มีลักษณะพิเศษเพิ่มเติม คือ
1. ค่าของรูทโหนดมีค่ามากกว่าค่าในต้นไม้ย่อยซ้าย
การท่องไปในทรี (Tree Traversal)
สามารถท่องเข้าไปในทรีเพื่อดูข้อมูลได้ 3 วิธีด้วยกัน คือ
1. Preorder
2. inorder
3. postorder
ในการท่องเข้าไปในทรีแต่ละแบบจะใช้สัญลักษณ์ดังนี้ Root = root node left = ต้นไม้ย่อยซ้ายของ
Root Right = ต้นไม้ย่อยขวาของ Root
วิธีการท่องเข้าไปในทรีแต่ละทรีแต่ละแบบจะมีลักษณะดังนี้
1. Preorder = Root Left Right
2. Inorder = Left Root Right
3. Postorder = Left Right Root
ตัวอย่างแสดงการท่องไปในทรี

วันพฤหัสบดีที่ 20 สิงหาคม พ.ศ. 2552
DTS06/20/08/2009
สรุป เรื่อง Queues
คิวเป็นโครงสร้างข้อมูลแบบลำดับลักษณะของคิวเราจะสามารถพบได้ในชีวิตประจำอยู่แล้ว เช่น การเข้าแถวตามคิวเพื่อรอการบริการต่างๆ ลำดับการสั่งการพิมพ์งานเป็นต้น ซึ่งจะเห็นได้ว่าลักษณะของการทำงานจะเป็นแบบของใครเข้าคิวก่อน จะได้รับการบริการก่อน เรียกได้ว่าเป็นลักษณะของการทำงาน
แบบ FIFO (First In ,First Out)
ลักษณะของคิวนั้นจะมีปลายสองข้าง ซึ่งข้างหนึ่งจะเป็นช่องทางสำหรับข้อมูลเข้าที่เรียกว่า Rear และอีกข้างหนึ่งซึ่งเป็นช่องทางสำหรับข้อมูลออก เรียกว่า Front ในการทำงานกับคิวที่ต้องมีการนำข้อมูลเข้าและออกนั้นจะต้องมีการตรวจสอบว่าคิวว่างหรือไม่เมื่อต้องการนำข้อมูลเข้า เพราะหากว่าคิวเต็มก็จะไม่สามารถทำการนำข้อมูลเข้าได้ เช่นเดียวกันเมื่อต้องการนำข้อมูลออกก็ต้องตรวจสอบอีกด้วยเช่นกันว่า ในคิวนั้นมีข้อมูลอยู่หรือไม่ หากคิวไม่มีข้อมูลก็จะไม่สามารถนำข้อมูลออกได้ เช่นเดียวกัน
การกระทำกับคิว การเพิ่มข้อมูลเข้าไปในคิวจะกระทำที่ตำแหน่ง Rrar หรือท้ายคิวและก่อนที่จะเพิ่มข้อมูลจะต้องตรวจสอบก่อนว่าคิวเต็มหรือไม่ โดยการเปรียบเทียบค่า Rear ว่าเท่ากับค่า Max queue หรือไม่ หากว่าค่า Rear=Max queue แสดงว่าคิวเต็มไม่สามารถเพิ่มข้อมูลเข้าไปได้ แต่หากไม่เท่า แสดงว่าคิวยังมีที่ว่างสามารถเพิ่มข้อมูลได้ เมื่อเพิ่มข้อมูลเข้าไปแล้ว ค่า Rear ก็จะเป็นค่าตำแหน่งท้ายคิวใหม่
ส่วนในการนำข้อมูลออกจากคิวจะกระทำที่ตำแหน่ง Front หรือส่วนที่เป็นหัวของคิว โดยก่อนที่จะนำข้อมูลออกจากคิวจะต้องมีการตรวจสอบก่อนว่ามีข้อมูลอยู่ในคิวหรือไม่ หากไม่มีข้อมูลในคิวหรือคิวว่างก็จะไม่สามารถนำข้อมูลออกจากคิวได้
คิวแบบวงกลม (Circular Queue) จะมีลักษณะเหมือนคิวธรรมดา คือ จะมีตัวชี้ Front และ Rear ที่แสดงตำแหน่งหัวคิวและท้ายคิวตามลำดับ โดยมี Front และ Rear จะมีการเลื่อนลำดับทุกครั้งเมื่อมีการนำข้อมูลเข้าและออกจากคิว แต่จะแตกต่างจากคิวธรรมดาตรงที่ว่า คิวธรรมดาเมื่อ Rear ชี้ตำแหน่งสุดท้ายของคิว จะทำให้เพิ่มข้อมูลเข้าไปในคิวอีกไม่ได้ เนื่องจากเนื่องจาก ค่า Rear=Max queue ซึ่งแสดงว่าคิวนั้นเต็มไม่สามารถเพิ่มข้อมูลเข้าไปได้อีก ทั้งๆ ที่ยังมีเนื้อที่ของคิวเหลืออยู่ก็ตาม ทำให้การใช้เนื้อที่ของคิวไม่มีประสิทธิภาพ
สำหรับคิวแบบวงกลม จะมีวิธีการจัดการกับปัญหานี้ คือ เมื่อมีข้อมูลเพิ่มเข้ามาในคิว ในลักษณะดังกล่าว คือ ขณะที่ Rear ชี้ตำแหน่งสุดท้ายของคิว ถ้าหากมีการเพิ่มค่าของ Rear จะสามารถวนกลับมาชี้ตำแหน่งแรกสุดของคิวได้ ซึ่งจะทำให้คิวมีลักษณะเป็นแบบวงกลมแสดงคิวแบบวงกลมที่ Rear สามารถวนกลับมาชี้ที่ตำแหน่งแรกสุดของคิว
คิวเป็นโครงสร้างข้อมูลแบบลำดับลักษณะของคิวเราจะสามารถพบได้ในชีวิตประจำอยู่แล้ว เช่น การเข้าแถวตามคิวเพื่อรอการบริการต่างๆ ลำดับการสั่งการพิมพ์งานเป็นต้น ซึ่งจะเห็นได้ว่าลักษณะของการทำงานจะเป็นแบบของใครเข้าคิวก่อน จะได้รับการบริการก่อน เรียกได้ว่าเป็นลักษณะของการทำงาน
แบบ FIFO (First In ,First Out)
ลักษณะของคิวนั้นจะมีปลายสองข้าง ซึ่งข้างหนึ่งจะเป็นช่องทางสำหรับข้อมูลเข้าที่เรียกว่า Rear และอีกข้างหนึ่งซึ่งเป็นช่องทางสำหรับข้อมูลออก เรียกว่า Front ในการทำงานกับคิวที่ต้องมีการนำข้อมูลเข้าและออกนั้นจะต้องมีการตรวจสอบว่าคิวว่างหรือไม่เมื่อต้องการนำข้อมูลเข้า เพราะหากว่าคิวเต็มก็จะไม่สามารถทำการนำข้อมูลเข้าได้ เช่นเดียวกันเมื่อต้องการนำข้อมูลออกก็ต้องตรวจสอบอีกด้วยเช่นกันว่า ในคิวนั้นมีข้อมูลอยู่หรือไม่ หากคิวไม่มีข้อมูลก็จะไม่สามารถนำข้อมูลออกได้ เช่นเดียวกัน
การกระทำกับคิว การเพิ่มข้อมูลเข้าไปในคิวจะกระทำที่ตำแหน่ง Rrar หรือท้ายคิวและก่อนที่จะเพิ่มข้อมูลจะต้องตรวจสอบก่อนว่าคิวเต็มหรือไม่ โดยการเปรียบเทียบค่า Rear ว่าเท่ากับค่า Max queue หรือไม่ หากว่าค่า Rear=Max queue แสดงว่าคิวเต็มไม่สามารถเพิ่มข้อมูลเข้าไปได้ แต่หากไม่เท่า แสดงว่าคิวยังมีที่ว่างสามารถเพิ่มข้อมูลได้ เมื่อเพิ่มข้อมูลเข้าไปแล้ว ค่า Rear ก็จะเป็นค่าตำแหน่งท้ายคิวใหม่
ส่วนในการนำข้อมูลออกจากคิวจะกระทำที่ตำแหน่ง Front หรือส่วนที่เป็นหัวของคิว โดยก่อนที่จะนำข้อมูลออกจากคิวจะต้องมีการตรวจสอบก่อนว่ามีข้อมูลอยู่ในคิวหรือไม่ หากไม่มีข้อมูลในคิวหรือคิวว่างก็จะไม่สามารถนำข้อมูลออกจากคิวได้
คิวแบบวงกลม (Circular Queue) จะมีลักษณะเหมือนคิวธรรมดา คือ จะมีตัวชี้ Front และ Rear ที่แสดงตำแหน่งหัวคิวและท้ายคิวตามลำดับ โดยมี Front และ Rear จะมีการเลื่อนลำดับทุกครั้งเมื่อมีการนำข้อมูลเข้าและออกจากคิว แต่จะแตกต่างจากคิวธรรมดาตรงที่ว่า คิวธรรมดาเมื่อ Rear ชี้ตำแหน่งสุดท้ายของคิว จะทำให้เพิ่มข้อมูลเข้าไปในคิวอีกไม่ได้ เนื่องจากเนื่องจาก ค่า Rear=Max queue ซึ่งแสดงว่าคิวนั้นเต็มไม่สามารถเพิ่มข้อมูลเข้าไปได้อีก ทั้งๆ ที่ยังมีเนื้อที่ของคิวเหลืออยู่ก็ตาม ทำให้การใช้เนื้อที่ของคิวไม่มีประสิทธิภาพ
สำหรับคิวแบบวงกลม จะมีวิธีการจัดการกับปัญหานี้ คือ เมื่อมีข้อมูลเพิ่มเข้ามาในคิว ในลักษณะดังกล่าว คือ ขณะที่ Rear ชี้ตำแหน่งสุดท้ายของคิว ถ้าหากมีการเพิ่มค่าของ Rear จะสามารถวนกลับมาชี้ตำแหน่งแรกสุดของคิวได้ ซึ่งจะทำให้คิวมีลักษณะเป็นแบบวงกลมแสดงคิวแบบวงกลมที่ Rear สามารถวนกลับมาชี้ที่ตำแหน่งแรกสุดของคิว
วันอังคารที่ 28 กรกฎาคม พ.ศ. 2552
DTS05/28/07/52
สแตก(stack)เป็นโครงสร้างข้อมูลที่ข้อมูลแบบเป็นลิเนียร์ลิสต์จะมีคุณสมบัติทีว่าการเพิ่ม หรือการลบข้อมูลในสแตก ลักษณะของสแตกคือข้อมูลที่ใส่หลังสุดหรือการนำเข้าไปหลังสุดแต่ว่าจะถูกนำออกมาจากสแตกเป็นอันดับแรกสุด ที่เรียกคุณสมบัตินี้ว่า LIFO (Last in First Out) การทำงานของสแตกนั้นจะทำที่ปลายข้างหนึ่งของสแตกเท่านั้น ดังนั้นสแตกจะต้องมีตัวชี้ตำแหน่งของข้อมูลบนสุดของสแตกด้วย
กระบวนการทำงานของสแตกจะประกอบไปด้วยการทำงานที่สำคัญ 3 กระบวนการ คือ
1.Push คือการนำข้อมูลเข้าไปใส่ลงในสแตก เช่น สแตก a ต้องการใส่ล b ในสแตก จะได้ Push (ab)
ในการเพิ่มข้อมูลลงในสแตกนั้นจะทำการตรวจสอบว่าในสแตก มีพื้นที่ว่างหรือไม่ถ้าสแตกเต็มก็จะไม่สามรถเพิ่มข้อมูลเข้าไปในสแตกได้อีก
2.Pop คือการนำข้อมูลออกจากส่วนบนสุดของสแตก ถ้าต้องการนำข้อมูลออกจากสแตก ถ้ามีสแตกมีสมาชิกเพียงตัวเดียวแล้วนำสมาชิกออกจากสแตก ก็จะเกิดภาวะสแตกว่าง คือไม่มีสมาชิกตัวใดอยู่ในแตกเลยเพราะฉะนั้นแล้วการนำข้อมูลออกจากสแตกควรตรวจสอบก่อนว่าสแตกว่างอยู่หรือป่าว
3.Stack Top คืออะไร เป็นการ copy คัดลอกไฟล์ข้อมูลที่อยู่ด้านบนสุดของสแตก แต่ไม่ได้นำเอาข้อมูลนั้นออกมาจากสแตก
การคำนวณ นิพจน์ของ stack
ในการเขียนนิพจน์เพื่อการคำนวณนั้นจะต้องคำนึงถึงความสำคัญของเครื่องหมายสำการคำนวณโดยจะแบ่งการเขียน ได้ เป็น 3 แบบ คือ
1.นิพจน์ infix นิพจน์นี้ operator จะอยู่ตรงกลางระหว่างตัวถูกดำเนินการ 2 ตัว
2.นิพจน์ postfix นิพจน์นี้แบบนี้ จะต้องเขียนตัวถูกดำเนินการตัวที่ 1 และ 2 ก่อน
แล้วจึงเขียน operator
3.นิพจน์ prefix นิพจน์แบบนี้ จะต้องเขียน operator ก่อนแล้วจึงเขียนตามด้วยตัวถูกดำเนินการตัวที่ 1 และ 2 ตามลำดับ
กระบวนการทำงานของสแตกจะประกอบไปด้วยการทำงานที่สำคัญ 3 กระบวนการ คือ
1.Push คือการนำข้อมูลเข้าไปใส่ลงในสแตก เช่น สแตก a ต้องการใส่ล b ในสแตก จะได้ Push (ab)
ในการเพิ่มข้อมูลลงในสแตกนั้นจะทำการตรวจสอบว่าในสแตก มีพื้นที่ว่างหรือไม่ถ้าสแตกเต็มก็จะไม่สามรถเพิ่มข้อมูลเข้าไปในสแตกได้อีก
2.Pop คือการนำข้อมูลออกจากส่วนบนสุดของสแตก ถ้าต้องการนำข้อมูลออกจากสแตก ถ้ามีสแตกมีสมาชิกเพียงตัวเดียวแล้วนำสมาชิกออกจากสแตก ก็จะเกิดภาวะสแตกว่าง คือไม่มีสมาชิกตัวใดอยู่ในแตกเลยเพราะฉะนั้นแล้วการนำข้อมูลออกจากสแตกควรตรวจสอบก่อนว่าสแตกว่างอยู่หรือป่าว
3.Stack Top คืออะไร เป็นการ copy คัดลอกไฟล์ข้อมูลที่อยู่ด้านบนสุดของสแตก แต่ไม่ได้นำเอาข้อมูลนั้นออกมาจากสแตก
การคำนวณ นิพจน์ของ stack
ในการเขียนนิพจน์เพื่อการคำนวณนั้นจะต้องคำนึงถึงความสำคัญของเครื่องหมายสำการคำนวณโดยจะแบ่งการเขียน ได้ เป็น 3 แบบ คือ
1.นิพจน์ infix นิพจน์นี้ operator จะอยู่ตรงกลางระหว่างตัวถูกดำเนินการ 2 ตัว
2.นิพจน์ postfix นิพจน์นี้แบบนี้ จะต้องเขียนตัวถูกดำเนินการตัวที่ 1 และ 2 ก่อน
แล้วจึงเขียน operator
3.นิพจน์ prefix นิพจน์แบบนี้ จะต้องเขียน operator ก่อนแล้วจึงเขียนตามด้วยตัวถูกดำเนินการตัวที่ 1 และ 2 ตามลำดับ
การบ้านเขียนโปรแกรม iostream.h และ stdio.h
#include
maim()
struct name {
char name[30];
char surname[40];
int age;
float salary;
int height;
int weight;
char status[10];
char birthday[40];
}name1;
printf("Insert Profile\n");
printf("Nane:");
scanf("%s",&name1.name);
printf("Surname:");
scanf("%s",&name1.surname);
printf("Age;");
scanf("%d",&name1.age);
printf("Salary:");
scanf("%f",&name1.salary);
printf("Height:");
scanf("%d",&name1.height);
printf("Weight:");
scanf("%d",&name1.weight);
printf("Status:");
scanf("%s",&name1.status);
print("Birthday:");
scanf("%s",&name1.birthday);
printf("\n\nYour Profile\n");
printf("Your name is : %s %s\n",name1.name,name1.surname);
printf("Age : %d\n",name1.age);
printf("Your Salary : %.2f\n",name1.salary);
printf("Height : %d and weight %d\n",name1.height,name1.weight);
printf("Status : %s\n",name1.status);
printf("Your BirthDay : %s\n",name1.birthday);
}
#include
#include
main()
{
struct neme {
char name[30];
char surname[40];
char add[44];
int age;
float salary;
int h;
int w;
char status;
char bd[40];
}name1;
cout << "Insert Profile\n";
cout << "Name : ";
cin >> name1.name;
cout << " Surname:";
cin >> name1.surname;
cout << " Add :";
gets (name1.add);
cout << "Age : ";
cin >> name1.age;
cout << "Salary :";
cin >> name1.salary;
cout << "Height :";
cin >> name1.h;
cout << "Weight :";
cin >> name1.w;
cout << "Status :";
cin >> name1.status;
cout << "Birthday :";
cin >> name1.bd;
}
maim()
struct name {
char name[30];
char surname[40];
int age;
float salary;
int height;
int weight;
char status[10];
char birthday[40];
}name1;
printf("Insert Profile\n");
printf("Nane:");
scanf("%s",&name1.name);
printf("Surname:");
scanf("%s",&name1.surname);
printf("Age;");
scanf("%d",&name1.age);
printf("Salary:");
scanf("%f",&name1.salary);
printf("Height:");
scanf("%d",&name1.height);
printf("Weight:");
scanf("%d",&name1.weight);
printf("Status:");
scanf("%s",&name1.status);
print("Birthday:");
scanf("%s",&name1.birthday);
printf("\n\nYour Profile\n");
printf("Your name is : %s %s\n",name1.name,name1.surname);
printf("Age : %d\n",name1.age);
printf("Your Salary : %.2f\n",name1.salary);
printf("Height : %d and weight %d\n",name1.height,name1.weight);
printf("Status : %s\n",name1.status);
printf("Your BirthDay : %s\n",name1.birthday);
}
#include
#include
main()
{
struct neme {
char name[30];
char surname[40];
char add[44];
int age;
float salary;
int h;
int w;
char status;
char bd[40];
}name1;
cout << "Insert Profile\n";
cout << "Name : ";
cin >> name1.name;
cout << " Surname:";
cin >> name1.surname;
cout << " Add :";
gets (name1.add);
cout << "Age : ";
cin >> name1.age;
cout << "Salary :";
cin >> name1.salary;
cout << "Height :";
cin >> name1.h;
cout << "Weight :";
cin >> name1.w;
cout << "Status :";
cin >> name1.status;
cout << "Birthday :";
cin >> name1.bd;
ตัวอย่าง สแตก(stack)ในชีวิตประจำวัน
1. การวางเหรียญซ้อนๆกัน
2. กล่องใส่แผ่นซีดีใส่แผ่นซีดีซ้อนๆกันไว้
3. การผับผ้าวางเป็นกองๆ
4. การวางหนังสือซ้อนกันเป็นหมวดหมู่
5. การใส่เสื้อผ้า
6. การใส่ถุงเท้ารองเท้า
7. การประกอบเครื่องยนต์
2. กล่องใส่แผ่นซีดีใส่แผ่นซีดีซ้อนๆกันไว้
3. การผับผ้าวางเป็นกองๆ
4. การวางหนังสือซ้อนกันเป็นหมวดหมู่
5. การใส่เสื้อผ้า
6. การใส่ถุงเท้ารองเท้า
7. การประกอบเครื่องยนต์
วันอังคารที่ 21 กรกฎาคม พ.ศ. 2552
DTS04/21/07/52
สรุปบทเรียน เรื่อง Linked List
ลิงค์ลิสต์เป็นวิธีการเก็บข้อมูลอย่างต่อเนื่องของอิลิเมรต์ต่างๆ โดยจะมีพอยเตอร์เป็นตัวเชื่อมต่อ ในแต่ละ
อิลิเมนท์ จะเรียกว่า โนด (Node) โดยในแต่ละโนดจะประกอบไปด้วย 2 ส่วน คือ Data จะเก็บข้อมูลของ
อิลิเมนท์ ในส่วนที่สอง คือ Link Field ทำหน้าที่เก็บตำแหน่งของโนดต่อไปในลิสต์ ในลิงค์ลิสต์จะมีตัวแปรสำหรับชี้ตำแหน่งลิสต์ซึ่งจะเป็นที่เก็บตำแหน่งเริ่มต้นของลิสต์ ก็คือ โหนดแรกของลิสต์นั่นเอง ถ้าในลิสต์ไม่มีข้อมูล ข้อมูลในโหนดแรกของลิสต์นั้จะเป็น Null
โครงสร้างของข้อมูลแบบลิงค์ลิสต์จะแบ่งเป็น 2 ส่วน คือ
Head Structure จะประกอบไปด้วย 3 ส่วน คือจำนวนโหนดในลิสต์ (Count) พอยเตอร์ที่ชี้ไปยัง
โหนดที่เข้าถึง (Pos)และพอยเตอร์ที่ชี้ไปยังโหนดข้อมูลแรกของลิสต์ (Head)
Data Node Structure ประกอบไปด้วยข้อมูลและพอยเตอร์ที่ชี้ไปยังข้อมูลถัดไป
กระบวนการทำงานของ Delete Node จะทำหน้าที่ลบสมาชิกในลิสต์ในลิสต์บริเวณตำแหน่งที่เราต้องการการนำข้อมูลนำเข้าข้อมูลและตำแหน่งและผลลัพธ์ที่ลิสต์ที่มีการเปลี่ยนแปลง
กระบวนการทำงาน Search list
หน้าที่ ค้นหาข้อมูลในลิสต์ที่ต้องการของข้อมูลนำเข้าลิสต์ ผลลัพธ์ ค่าจริงจะถ้าพบข้อมูล ค่าเท็จถ้าไม่พบข้อมูลนั้น
Traverse คือ หน้าที่ท่องไปในลิสต์เพื่อเข้าถึงและ ประมวลผลข้อมูลนำเข้าลิสต์ ผลลัพธ์ ขึ้นกับการประมวลผล
เช่นการเปลี่ยนแปลงค่า ใน node,รวมกับฟิลด์ในลิสต์คำนวณค่าเฉลี่ยของฟิลด์ นั้นเป็นต้น
Retrieve Node หน้าที่ คือ หาตำแหน่งข้อมูลจากลิสต์ข้อมูลนำเข้าลิสต์ ผลลัพธ์คือ ตำแหน่งข้อมูลที่อยู่ใลสต์
ฟังก์ชั่น เป็น หน้าที่ ทดสอบว่าลิสต์ว่างข้อมูลนำเข้าลิสต์ ผลลัพธ์ ถ้าเป็นจริง
ลิสต์ว่าง ถ้าเป็นเท็จ ลิสต์ไม่ว่าง การทำงานของ FullList ทดสอบหน้าที่ ว่าลิสต์เต็มหรือไม่มีข้อมูลนำเข้าลิสต์ ผลลัพธ์คือ ถ้า เป็นจริง หน่วยความจำเต็ม เป็นเท็จ สามารถมีโหนดอื่น กระบวนการทำงานของ Destroy list หน้าที่คือ การทำลายลิสต์ ข้อมูลนำเข้าคือ ลิสต์และผลลัพธ์ คือไม่มีลิสต์

ลิงค์ลิสต์เป็นวิธีการเก็บข้อมูลอย่างต่อเนื่องของอิลิเมรต์ต่างๆ โดยจะมีพอยเตอร์เป็นตัวเชื่อมต่อ ในแต่ละ
อิลิเมนท์ จะเรียกว่า โนด (Node) โดยในแต่ละโนดจะประกอบไปด้วย 2 ส่วน คือ Data จะเก็บข้อมูลของ
อิลิเมนท์ ในส่วนที่สอง คือ Link Field ทำหน้าที่เก็บตำแหน่งของโนดต่อไปในลิสต์ ในลิงค์ลิสต์จะมีตัวแปรสำหรับชี้ตำแหน่งลิสต์ซึ่งจะเป็นที่เก็บตำแหน่งเริ่มต้นของลิสต์ ก็คือ โหนดแรกของลิสต์นั่นเอง ถ้าในลิสต์ไม่มีข้อมูล ข้อมูลในโหนดแรกของลิสต์นั้จะเป็น Null
โครงสร้างของข้อมูลแบบลิงค์ลิสต์จะแบ่งเป็น 2 ส่วน คือ
Head Structure จะประกอบไปด้วย 3 ส่วน คือจำนวนโหนดในลิสต์ (Count) พอยเตอร์ที่ชี้ไปยัง
โหนดที่เข้าถึง (Pos)และพอยเตอร์ที่ชี้ไปยังโหนดข้อมูลแรกของลิสต์ (Head)
Data Node Structure ประกอบไปด้วยข้อมูลและพอยเตอร์ที่ชี้ไปยังข้อมูลถัดไป
กระบวนการทำงานของ Delete Node จะทำหน้าที่ลบสมาชิกในลิสต์ในลิสต์บริเวณตำแหน่งที่เราต้องการการนำข้อมูลนำเข้าข้อมูลและตำแหน่งและผลลัพธ์ที่ลิสต์ที่มีการเปลี่ยนแปลง
กระบวนการทำงาน Search list
หน้าที่ ค้นหาข้อมูลในลิสต์ที่ต้องการของข้อมูลนำเข้าลิสต์ ผลลัพธ์ ค่าจริงจะถ้าพบข้อมูล ค่าเท็จถ้าไม่พบข้อมูลนั้น
Traverse คือ หน้าที่ท่องไปในลิสต์เพื่อเข้าถึงและ ประมวลผลข้อมูลนำเข้าลิสต์ ผลลัพธ์ ขึ้นกับการประมวลผล
เช่นการเปลี่ยนแปลงค่า ใน node,รวมกับฟิลด์ในลิสต์คำนวณค่าเฉลี่ยของฟิลด์ นั้นเป็นต้น
Retrieve Node หน้าที่ คือ หาตำแหน่งข้อมูลจากลิสต์ข้อมูลนำเข้าลิสต์ ผลลัพธ์คือ ตำแหน่งข้อมูลที่อยู่ใลสต์
ฟังก์ชั่น เป็น หน้าที่ ทดสอบว่าลิสต์ว่างข้อมูลนำเข้าลิสต์ ผลลัพธ์ ถ้าเป็นจริง
ลิสต์ว่าง ถ้าเป็นเท็จ ลิสต์ไม่ว่าง การทำงานของ FullList ทดสอบหน้าที่ ว่าลิสต์เต็มหรือไม่มีข้อมูลนำเข้าลิสต์ ผลลัพธ์คือ ถ้า เป็นจริง หน่วยความจำเต็ม เป็นเท็จ สามารถมีโหนดอื่น กระบวนการทำงานของ Destroy list หน้าที่คือ การทำลายลิสต์ ข้อมูลนำเข้าคือ ลิสต์และผลลัพธ์ คือไม่มีลิสต์

วันอาทิตย์ที่ 12 กรกฎาคม พ.ศ. 2552
DTS03/12/07/52
สรุปการเรียน Lecture 3
เรื่อง Set and Sting โครงสร้างข้อมูลแบบเซ็ตจะเป็นโครงสร้างข้อมูลแต่ละตัวที่ไม่มีความสัมพันธ์กับภาษาซีแต่สามารถใช้หลักการดำเนินงานแบบเซ็ตมาใช้ได้ ตัวดำเนินการของเซ็ตนั้น จะประกอบไปด้วย
-set intersection
-set union
-set difference
โครงสร้างข้อมูลแบบสตริงจะแตกต่างไปจากโครงสร้างข้อมูลแบบเซ็ต คือ สตริงเป็นข้อมูลที่ประกอบไปด้วย อักษร ตัวเลข หรือเครื่องหมายต่างๆ ที่เรียงต่อๆ กันรวมทั้งช่องว่าง โครงสร้างแบบสตริงนั้น ความยาวของสตริงจะถูกกำหนดโดยขนาดของสตริง โดยขนาดของสติงนั้นจะต้องจองเนื้อที่ในหน่วยความจำให้กับ \0ด้วย
เช่น "This is the sun" จะเป็นข้อมูลยาว 16 อักขระ โดยจุดสิ้นสุดของ สตริงนั้นจะต้องจบด้วย \0 หรือ null character เช่น
char a[]={'s','u','n','\0'};
chsr a[]="sun";
ในการกำหนดโครงสร้างแบบสตริงนั้นทำได้หลายแบบ คือ กำหนดเป็นสตริงที่มีค้าคงตัวและกำหนดใช้ตัวแปร
อะเรย์หรือพอยเตอร์ ในการกำหนดค่าคงตัวสตริงสามารถกำหนดได้ทั้งนอกและในฟังก์ชันถ้าเรากำหนดไว้นอกฟังก์ชัน ชื่อค่าคงตัวจะเป็นพอยเตอร์ชี้ไปยังหน่วยความจำที่เก็บสตริงนั้น ถ้าเรากำหนดไว้ในฟังก์ชัน ก็จะเป็น พอยเตอร์ไปเก็บยังหน่วยความที่ตัวของมันเอง
โครงสร้างข้อมูลแบบสตริงในการกำหนดค่าคงตัวสตริงให้แก่พอยต์เตอร์กับอะเรย์สามารถกำหนดค่าคงตัวสตริงให้
พอยเตอร์อะเรย์ได้ในฐานะเริ่มต้น เช่น
main(){
char name[]="wisit.";
char *lastname="rinjan.";
printf("%s%s",name,lastname);
}
ถ้าหามีสตริงจำนวนมากก็ควรที่จะทำให้เป็นอะเรย์ของสตริง เพื่อที่จะเขียนโปรแกรมได้สะดวก ในการสร้างอะเรย์ของสตริง
เรื่อง Set and Sting โครงสร้างข้อมูลแบบเซ็ตจะเป็นโครงสร้างข้อมูลแต่ละตัวที่ไม่มีความสัมพันธ์กับภาษาซีแต่สามารถใช้หลักการดำเนินงานแบบเซ็ตมาใช้ได้ ตัวดำเนินการของเซ็ตนั้น จะประกอบไปด้วย
-set intersection
-set union
-set difference
โครงสร้างข้อมูลแบบสตริงจะแตกต่างไปจากโครงสร้างข้อมูลแบบเซ็ต คือ สตริงเป็นข้อมูลที่ประกอบไปด้วย อักษร ตัวเลข หรือเครื่องหมายต่างๆ ที่เรียงต่อๆ กันรวมทั้งช่องว่าง โครงสร้างแบบสตริงนั้น ความยาวของสตริงจะถูกกำหนดโดยขนาดของสตริง โดยขนาดของสติงนั้นจะต้องจองเนื้อที่ในหน่วยความจำให้กับ \0ด้วย
เช่น "This is the sun" จะเป็นข้อมูลยาว 16 อักขระ โดยจุดสิ้นสุดของ สตริงนั้นจะต้องจบด้วย \0 หรือ null character เช่น
char a[]={'s','u','n','\0'};
chsr a[]="sun";
ในการกำหนดโครงสร้างแบบสตริงนั้นทำได้หลายแบบ คือ กำหนดเป็นสตริงที่มีค้าคงตัวและกำหนดใช้ตัวแปร
อะเรย์หรือพอยเตอร์ ในการกำหนดค่าคงตัวสตริงสามารถกำหนดได้ทั้งนอกและในฟังก์ชันถ้าเรากำหนดไว้นอกฟังก์ชัน ชื่อค่าคงตัวจะเป็นพอยเตอร์ชี้ไปยังหน่วยความจำที่เก็บสตริงนั้น ถ้าเรากำหนดไว้ในฟังก์ชัน ก็จะเป็น พอยเตอร์ไปเก็บยังหน่วยความที่ตัวของมันเอง
โครงสร้างข้อมูลแบบสตริงในการกำหนดค่าคงตัวสตริงให้แก่พอยต์เตอร์กับอะเรย์สามารถกำหนดค่าคงตัวสตริงให้
พอยเตอร์อะเรย์ได้ในฐานะเริ่มต้น เช่น
main(){
char name[]="wisit.";
char *lastname="rinjan.";
printf("%s%s",name,lastname);
}
ถ้าหามีสตริงจำนวนมากก็ควรที่จะทำให้เป็นอะเรย์ของสตริง เพื่อที่จะเขียนโปรแกรมได้สะดวก ในการสร้างอะเรย์ของสตริง
วันจันทร์ที่ 29 มิถุนายน พ.ศ. 2552
DTS02-/24/06/52
สรุป บทเรียน Lecture 2 Array and Record
อะเรย์เป็นโครงสร้างข้อมูลที่มีลักษณะคล้ายเซ็ตในคณิตศาสตร์ คือ อะเรย์จะประกอบด้วยสมาชิกที่มีจำนวนคงที่ มีรูปแบบข้อมูลเป็นแบบเดียวกัน สมาชิกแต่ละตัวใช้เนื้อที่จัดเก็บที่มีขนาดเดียวกัน
การกำหนดอะเรย์จะต้องกำหนดชื่ออะเรย์ พร้อมกับ subscriptซึ่งเป็นตัวกำหนดขอบเขตของอะเรย์มีได้มากกว่า 1 ตัว อะเรย์มี subscript มากกว่า 1 ตัวจะเรียกว่า อะเรย์หลายมิติการกำหนด subscript แต่ละตัวจะประกอบไปด้วยค่าสูงสุดและค่าต่ำสุดของ subscript นั้น
subscript คือค่าต่ำสุดต้องมีค่าน้อยกว่าหรือเท่ากับค่าสูงสุดเสมอ
อะเรย์เป็นโครงสร้างข้อมูลที่มีลักษณะคล้ายเซ็ตในคณิตศาสตร์ คือ อะเรย์จะประกอบด้วยสมาชิกที่มีจำนวนคงที่ มีรูปแบบข้อมูลเป็นแบบเดียวกัน สมาชิกแต่ละตัวใช้เนื้อที่จัดเก็บที่มีขนาดเดียวกัน
การกำหนดอะเรย์จะต้องกำหนดชื่ออะเรย์ พร้อมกับ subscriptซึ่งเป็นตัวกำหนดขอบเขตของอะเรย์มีได้มากกว่า 1 ตัว อะเรย์มี subscript มากกว่า 1 ตัวจะเรียกว่า อะเรย์หลายมิติการกำหนด subscript แต่ละตัวจะประกอบไปด้วยค่าสูงสุดและค่าต่ำสุดของ subscript นั้น
subscript คือค่าต่ำสุดต้องมีค่าน้อยกว่าหรือเท่ากับค่าสูงสุดเสมอ
ค่าต่ำสุดเรียกว่า ขอบเขตล่าง
ค่าสูงสุดเรียกว่า ขอบเขตบน
อะเรย์ 1 มิติ รูปแบบ data-type array-name[expression]
data-type คือ ประเภทของข้อมูลอะเรย์ เช่น int float char
array-name คือ ชื่อของอะเรย์
expression คือ นิพจน์จำนวนเต็มซึ่งระบุจำนวนสมาชิกของอะเรย์
ค่าสูงสุดเรียกว่า ขอบเขตบน
อะเรย์ 1 มิติ รูปแบบ data-type array-name[expression]
data-type คือ ประเภทของข้อมูลอะเรย์ เช่น int float char
array-name คือ ชื่อของอะเรย์
expression คือ นิพจน์จำนวนเต็มซึ่งระบุจำนวนสมาชิกของอะเรย์
อะเรย์ 1 มิติ หมายถึง คอมพิวเตอร์จะจองเนื้อที่ในหน่วยความจำสำหรับตัวแปร ที่เป็นตัวอักษรให้เป็นตัวแปรชุดชนิด character เช่นสมาชิก 4 ตัว โดยหน่วยความจำจะเตรียมเนื้อที่ให้ 1 byte สำหรับชื่อตัวแปร เป็นการข้อมูลเพียงแถวเดียว
อะเรย์ 2 มิติ รูปแบบ type array-name[n][m];
type หมายถึง ชนิดของตัวแปรที่ต้องการประกาศ
array-name หมายถึง ชื่อของตัวแปรที่ต้องการประกาศเป็นอะเรย์
type หมายถึง ชนิดของตัวแปรที่ต้องการประกาศ
array-name หมายถึง ชื่อของตัวแปรที่ต้องการประกาศเป็นอะเรย์
n หมายถึง ตัวเลขที่แสดงตำแหน่งของแถว m หมายถึง ตัวเลขที่แสดงตำแหน่งของคอลัมน์
ตัวอย่างอะเรย์ 2 มิติ
กำหนดค่าเริ่มต้นให้ int a[4][8]
Structure
เป็นโครงสร้างข้อมูลที่ประกอบขึ้นจากข้อมูลต่างประเภทกัน ซึ่งรวมกันเป็น 1ชุดข้อมูลคือจะประกอบด้วย data element field ต่างประเภทซึ่งรวมกันอยู่ structure คือ โครงสร้างที่มีข้อมูลแต่ละประเภทที่แตกต่างกัน structure อาจจะมีสมาชิกเป็น ทศนิยม จำนวนเต็ม อักขระ อยู่รวมกัน
คำหลักที่ต้องมีเสมอคือ Structure
struc-name ชื่อกลุ่ม
type ชนิดของตัวแปรที่อยู่ในกลุ่ม
name-n ชื่อของตัวแปรชนิดโครงสร้าง
struc-variable ชื่อตัวแปรที่มีโครงสร้าง
structure จะเป็นการกำหนดให้ตัวแปร employee เป็นชื่อของกลุ่ม structure ที่ประกอบไปด้วย ตัวแปร name[20],age และ salary โดยมีตัวแปร personel เป็นตัวแปรชนิดโครงสร้างที่มีข้อมูลแบบเดียวกับตัวแปรemployee การอ้างถึงตัวแปรที่อยู่ในตัวแปรชนิดโครงสร้างสามารถอ้างถึงตัวแปรที่อยู่ในตัวแปรชนิดโครงสร้างได้รูปแบบ struct-variable.element-name struct-variable คือชื่อตัวแปรชนิดโครงสร้าง
element-name คือชื่อตัวแปรที่อยู่ภายใน structure
การบ้านโครงสร้างข้อมูล
struct family {
char fam_name[30];
char dad_name[50];
int age_dad;
char mom_name[50];
int age_mom;
char son_name;[50];
int age_son;
float fam_income;
} family1;
ตัวอย่าง
family1.age_dad=40;
family1.fam_income=50000;
char fam_name[30];
char dad_name[50];
int age_dad;
char mom_name[50];
int age_mom;
char son_name;[50];
int age_son;
float fam_income;
} family1;
ตัวอย่าง
family1.age_dad=40;
family1.fam_income=50000;
วันพฤหัสบดีที่ 25 มิถุนายน พ.ศ. 2552
ประวัติ
ชื่อ-นามสกุล นายวิสิทธิ์ รินจันทร์
ชื่อเล่น ตั้ม
วัน เดือน ปีเกิด 22 กันยายน พ.ศ. 2531
ส่วนสูง 173
น้ำหนัก 65
การศึกษา ศึกษาอยู่ที่ มหาวิทยาลัยราชภัฏสวนดุสิต
อาชีพ นักศึกษา
คติประจำใจ จงสร้าง บุญและทำความดีบนโลกนี้
สมัครสมาชิก:
บทความ (Atom)



{kind=link}